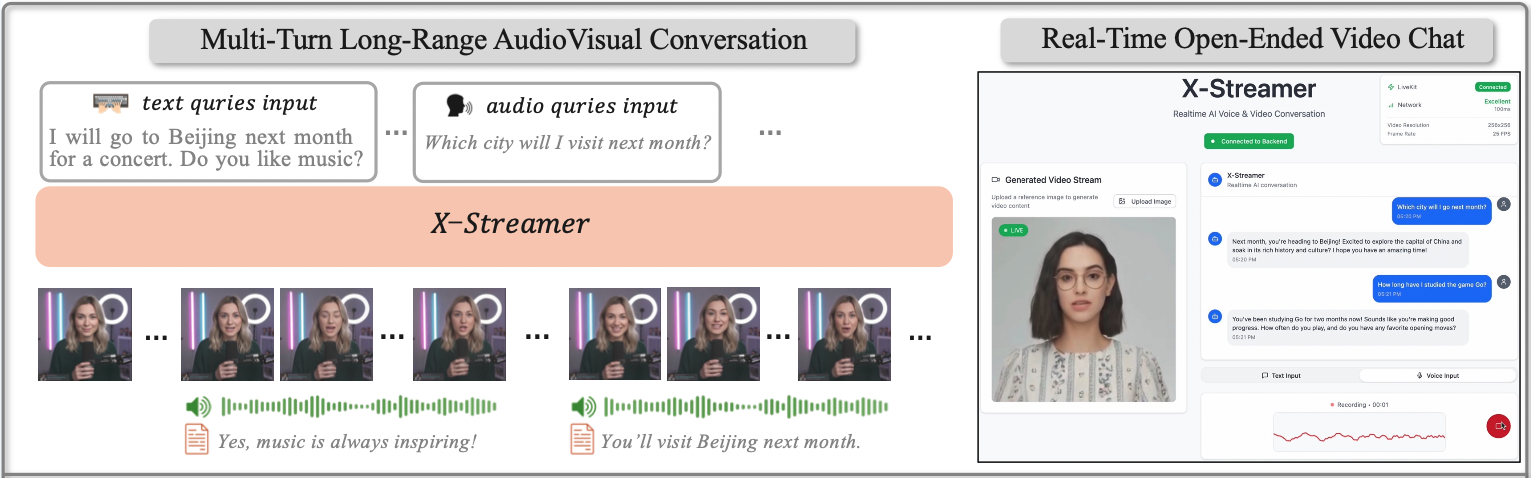
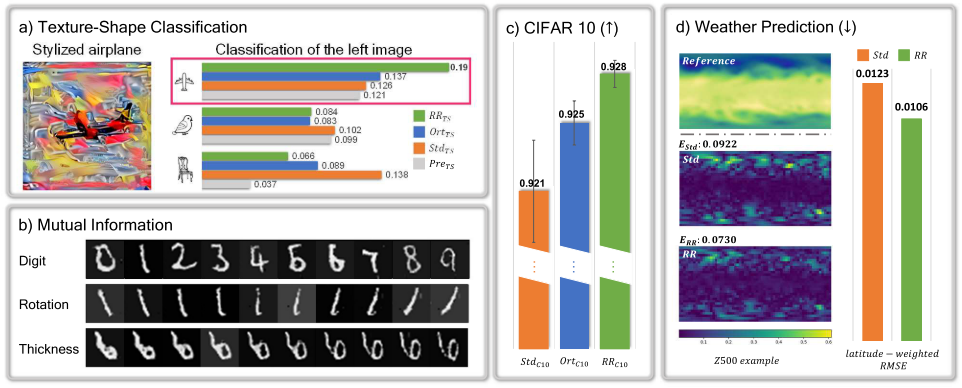
About Me
I am currently a Research Scientist at Meta. I earned my Ph.D. in Computer Science from the Technical University of Munich, where I was mentored by Prof. Nils Thuerey. Prior to that, I obtained an M.Eng. degree from the School of Mechanical Science and Engineering at Huazhong University of Science and Technology, and a B.Eng. degree from the College of Mechanical and Electrical Engineering at Central South University.
My research interests lie in computer graphics and vision, video generation, and physics-based simulation. If you are interested in my research, feel free to contact me via email!
Keywords of Recent Research
-

Inference Acceleration
-

Video Generation
-
MultiModal Large Language Model
-
Diffusion Model
Education
-
Technical University of Munich
2017 — 2022Ph.D., Department of Computer Science
Research Topic: Video Generation; Deep Learning; Physics-based Simulation
Advisor: Prof. Nils Thuerey -
Huazhong University of Science and Technology
2015 — 2017Master, School of Mechanical Science and Engineering, CAD Center
Research Topic: Multi-disciplinary Simulation and Optimization Algorithms
Advisor: Prof. Yizhong Wu -
Central South University
2011 — 2015Bachelor, College of Mechanical and Electrical Engineering
Major: Mechanical Design & Manufacturing and Automation
Career
-
Meta
2026.1 — nowI work as a Research Scientist developing cutting-edge video generation algorithms and advancing quantization and distillation techniques to enable high-performance, efficient inference.
-
Tiktok, Bytedance
2022.12 — 2026.1I worked as a Research Scientist, focusing on cutting-edge video generation algorithms for virtual human-related applications.
-
National University of Singapore
2022.2 — 2022.4I worked as a Research Assistant in the CVML Lab under the guidance of Prof. Angela Yao, where I focused on developing generative algorithms for 3D hand reconstruction from 2D images.
-
Bosch
2014.8 — 2014.12I worked as an Assistant Engineer in the R&D department, specializing in the design and testing of starters.